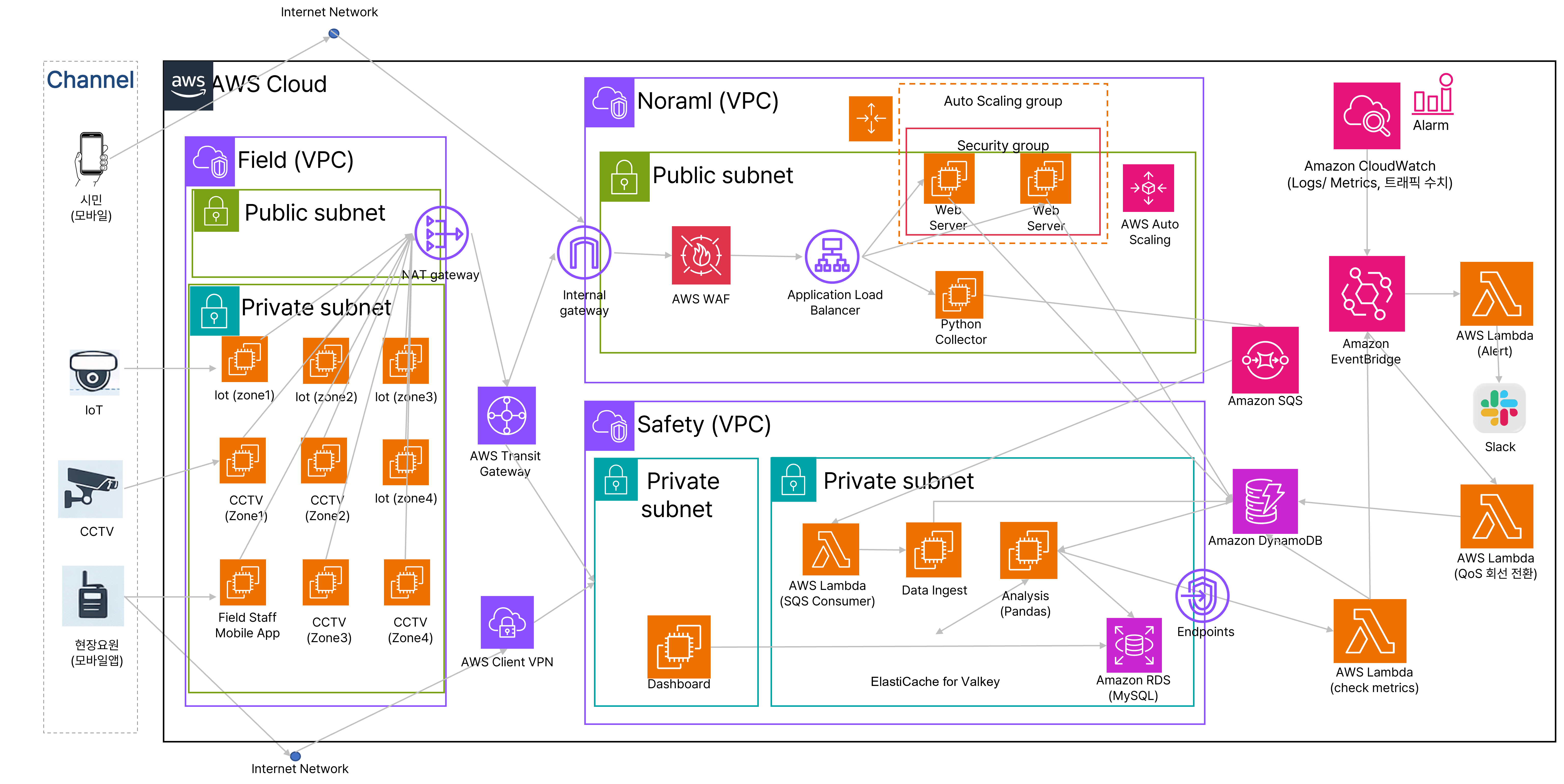
AWS 아키텍처
3-VPC 분리로 구현한
통신 생존성 아키텍처
재난·혼잡 상황에서도 관제 통신이 절대 끊기지 않도록, Field·Normal·Safety VPC를 완전 분리하고 자동 전환 파이프라인으로 연결했습니다.
Channel
모바일
Internet
Field VPC 현장 데이터 수집
Public Subnet
Private Subnet
Zone 1~4
Zone 1~4
Mobile App
Normal VPC 트래픽 흡수 · 수집
Public Subnet
Balancer
Collector
× 2
Safety VPC 분석 · 판단 · 알림
Private Subnet (분석)
SQS Consumer
Pandas
Private Subnet (데이터)
Valkey
🔒 VPN으로만 접근 (비상 경로)
자동화 · 모니터링 레이어 (VPC 공통)
CloudWatch
ALB RequestCount
WAF Blocked 모니터링
WAF Blocked 모니터링
→Alarm
EventBridge
룰 매칭
Lambda 트리거
Lambda 트리거
→
Lambda
check metrics
check metrics
모드 확인
주기적 상태 판단
주기적 상태 판단
→
Lambda
QoS 전환
QoS 전환
WAF Rule 변경
ALB Listener 변경
ALB Listener 변경
→
Lambda
Alert
Alert
Slack 알림
재난모드 전환 안내
재난모드 전환 안내
→
Slack
현장요원·관제실
즉시 알림
즉시 알림